Error Analysis
Error Analysis is Truesight's structured process for discovering evaluation criteria from your data. Instead of guessing what to evaluate, you examine real examples and let patterns emerge. The process follows two phases: Open Coding and Axial Coding.
Why Error Analysis?
Generic scores like "helpfulness" or "coherence" don't capture what matters for your specific use case. Error Analysis helps you build evaluation criteria grounded in your domain expertise by systematically reviewing your AI's actual outputs.
The result is a set of well-defined categories that reflect real failure modes, not abstract metrics.
Open Coding
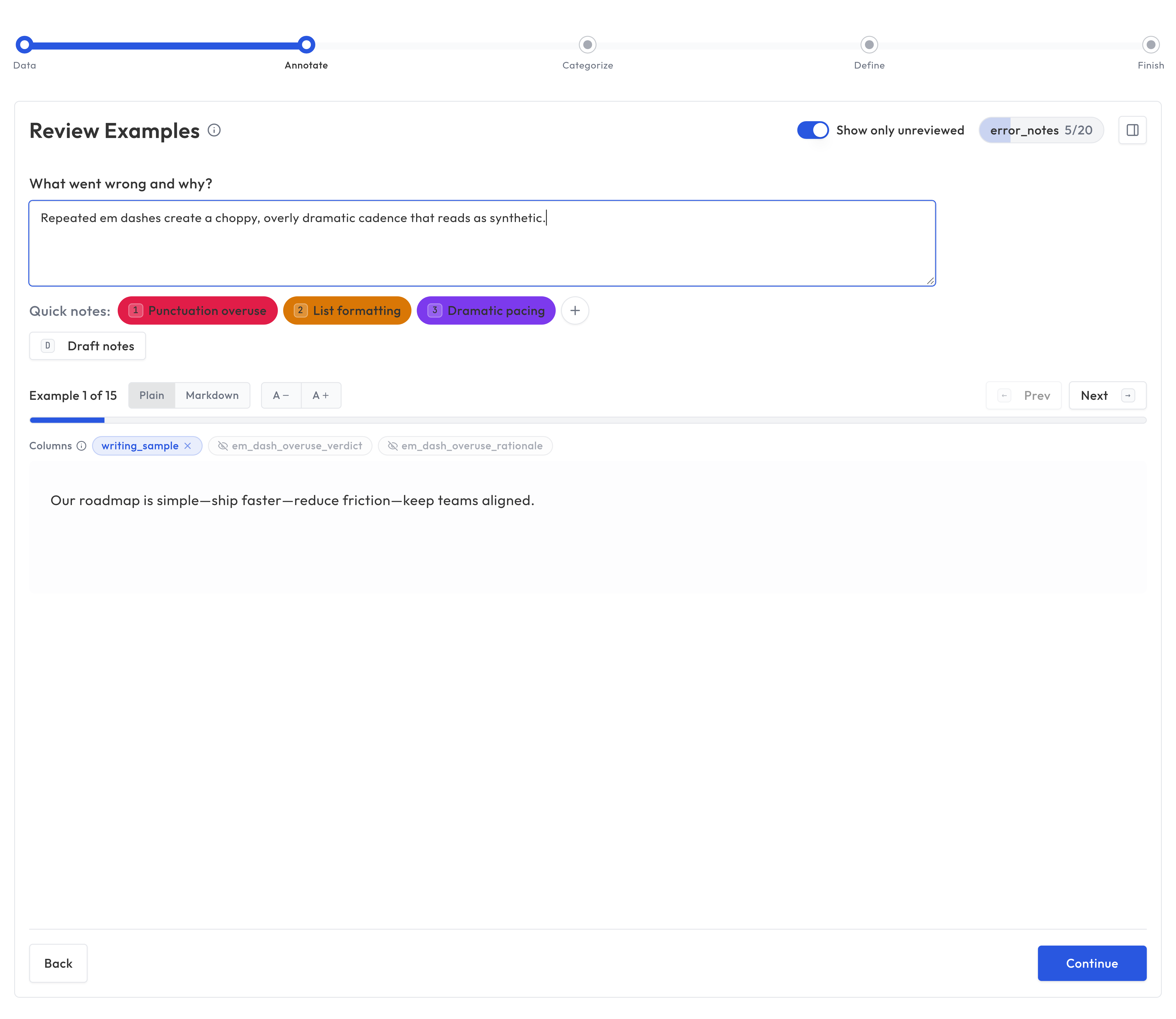
Open Coding is the first phase. You review examples from your dataset one at a time and note any patterns you observe.
How it works
- Navigate to Error Analysis in the sidebar and select a dataset
- You're shown one example at a time, including the input, output, and any other columns. If the dataset contains images, they are displayed alongside the text.
- For each example, write notes describing what you observe. Use Quick notes to quickly insert reusable note text when helpful.
- Move through examples at your own pace
What to look for
Note anything that stands out, whether positive or negative:
- Factual errors or hallucinations
- Missing information that should have been included
- Tone or style issues
- Correct handling of edge cases
- Particularly good or bad reasoning
- For images: layout problems, unclear labels, misleading visuals, or accessibility issues
There's no wrong answer in Open Coding. The goal is to capture your observations without worrying about organization yet.
Tips for effective Open Coding
- Be specific: "Hallucinated a statistic" is more useful than "wrong"
- Use natural language: Write notes the way you'd describe the issue to a colleague
- Don't over-think it: Speed matters more than perfection in this phase
- Review at least 20 examples: You need enough data for meaningful patterns to emerge
Axial Coding
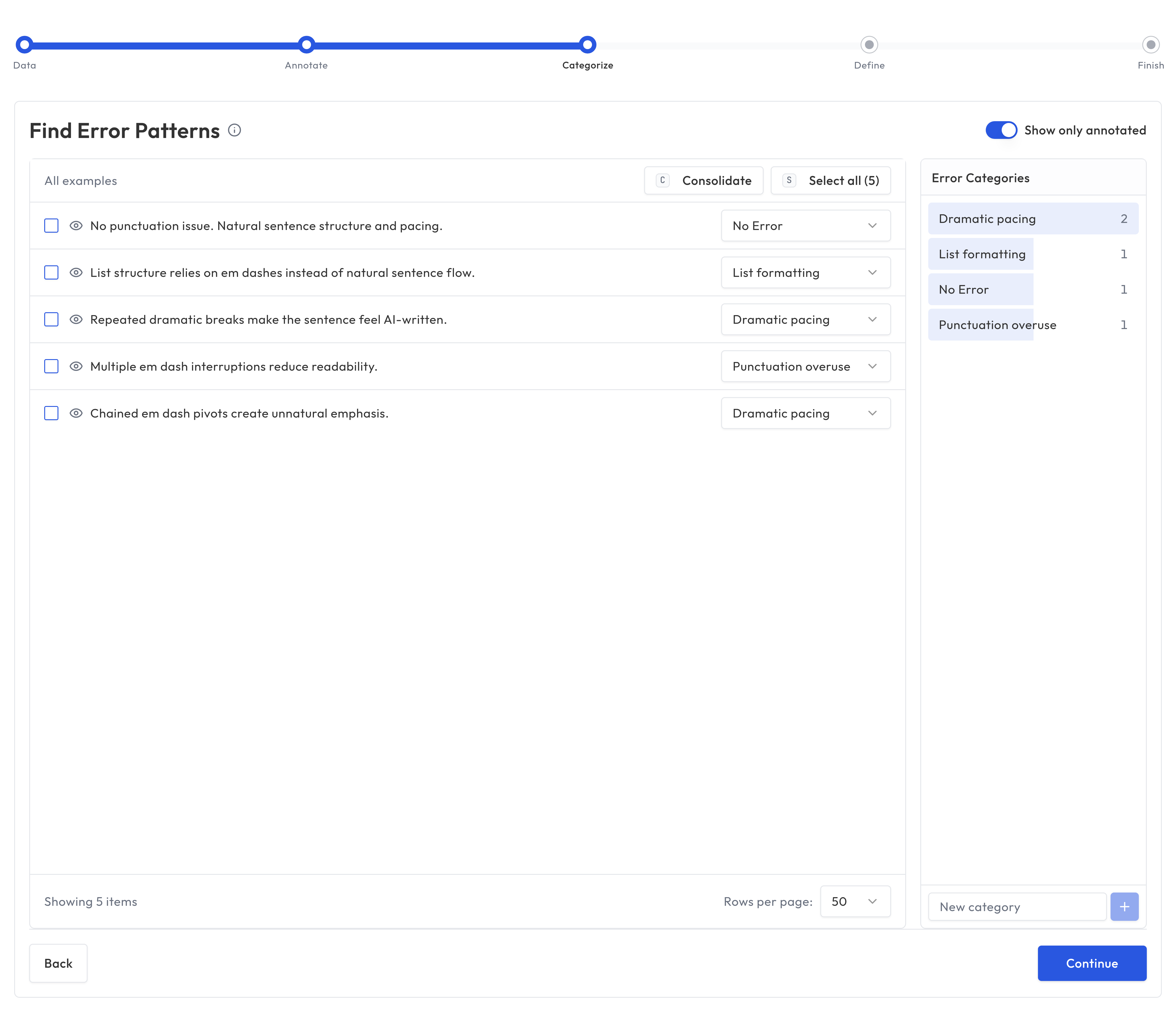
Axial Coding is the second phase. Here, you take the notes from Open Coding and organize them into categories.
How it works
- Truesight presents your notes and suggests clusters of related observations
- You review the suggested groupings and adjust them
- Name each category with a clear, descriptive label
- Add descriptions that explain what each category means
From notes to categories
For example, if your Open Coding notes include:
- "Made up a fact"
- "Cited a source that doesn't exist"
- "Confused two different concepts"
- "Stated an opinion as fact"
These might all group into a category called Factual Accuracy, with a description like: "The response contains only verifiable facts and correctly attributes claims."
Or if your notes include:
- "Response was cold and dismissive"
- "Used jargon the customer wouldn't understand"
- "Didn't acknowledge the customer's frustration"
- "Sounded like a form letter"
These might group into Professional Tone: "The response is warm, empathetic, and uses language appropriate for the audience."
And notes like:
- "Didn't mention the return deadline"
- "Said they'd help but didn't explain how"
- "Left out the shipping cost"
- "Answered the question but skipped next steps"
These might become Response Completeness: "The response addresses the full question and includes all relevant details, next steps, and deadlines."
Tips for effective Axial Coding
- Aim for 3 to 7 categories: Fewer than 3 is too coarse; more than 7 is hard to manage
- Make categories actionable: Each category should clearly describe what "good" looks like
- Avoid overlap: If two categories frequently apply to the same examples, consider merging them
- Think about pass/fail: Each category will become an evaluation criterion, so it should be clear when an output passes or fails
Using Error Analysis results
Your Axial Coding categories feed directly into the evaluation building process:
- In Guided Setup, you can import categories as evaluation criteria
- As judge instructions, the category descriptions help AI judges understand what to look for
- For team alignment, categories serve as a shared vocabulary for quality assessment
Iterating on your analysis
Error Analysis isn't a one-time process. As your AI system evolves and you encounter new patterns, you can:
- Run Open Coding on new datasets to discover emerging issues
- Refine existing categories based on evaluation results
- Add new categories as your understanding deepens
The goal is continuous refinement. Your evaluation criteria should grow and improve alongside your AI system.